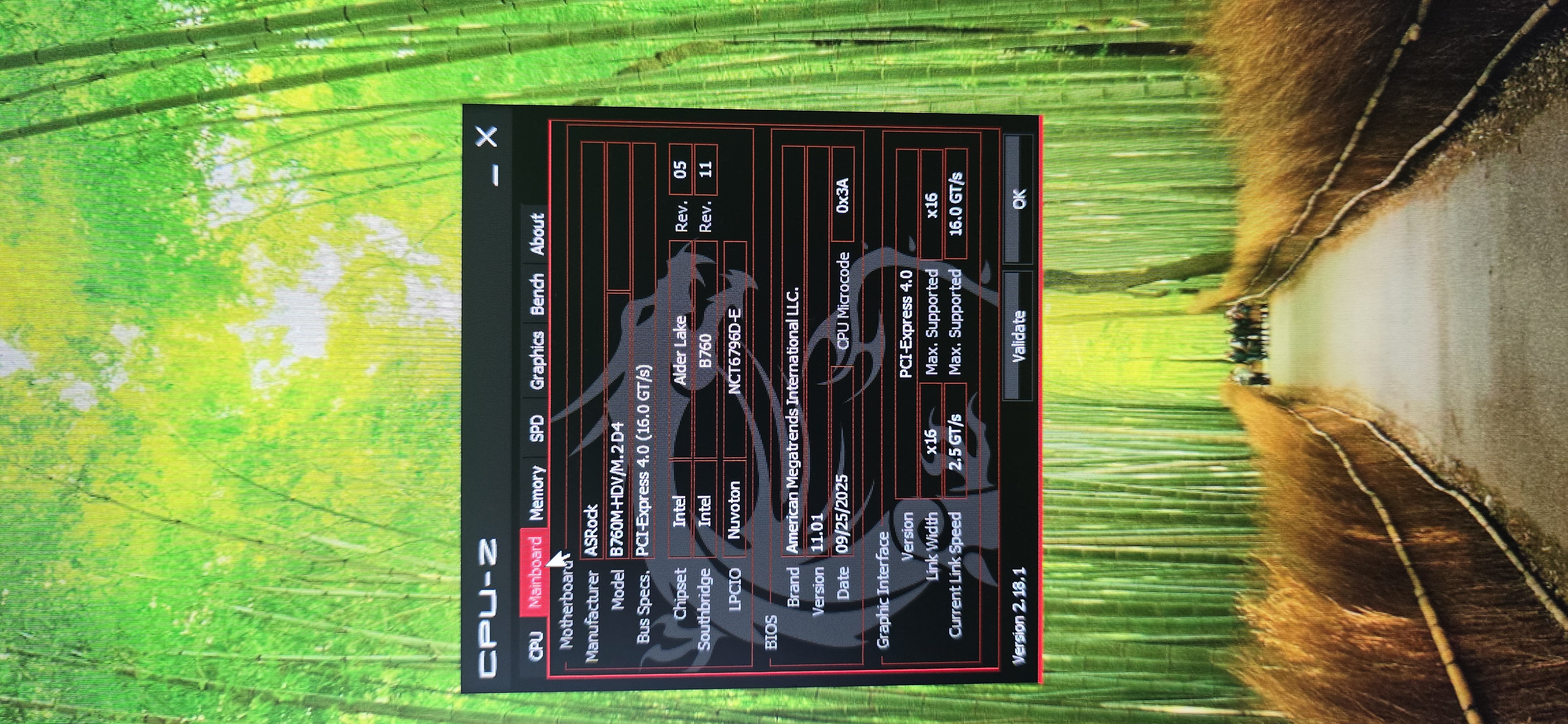
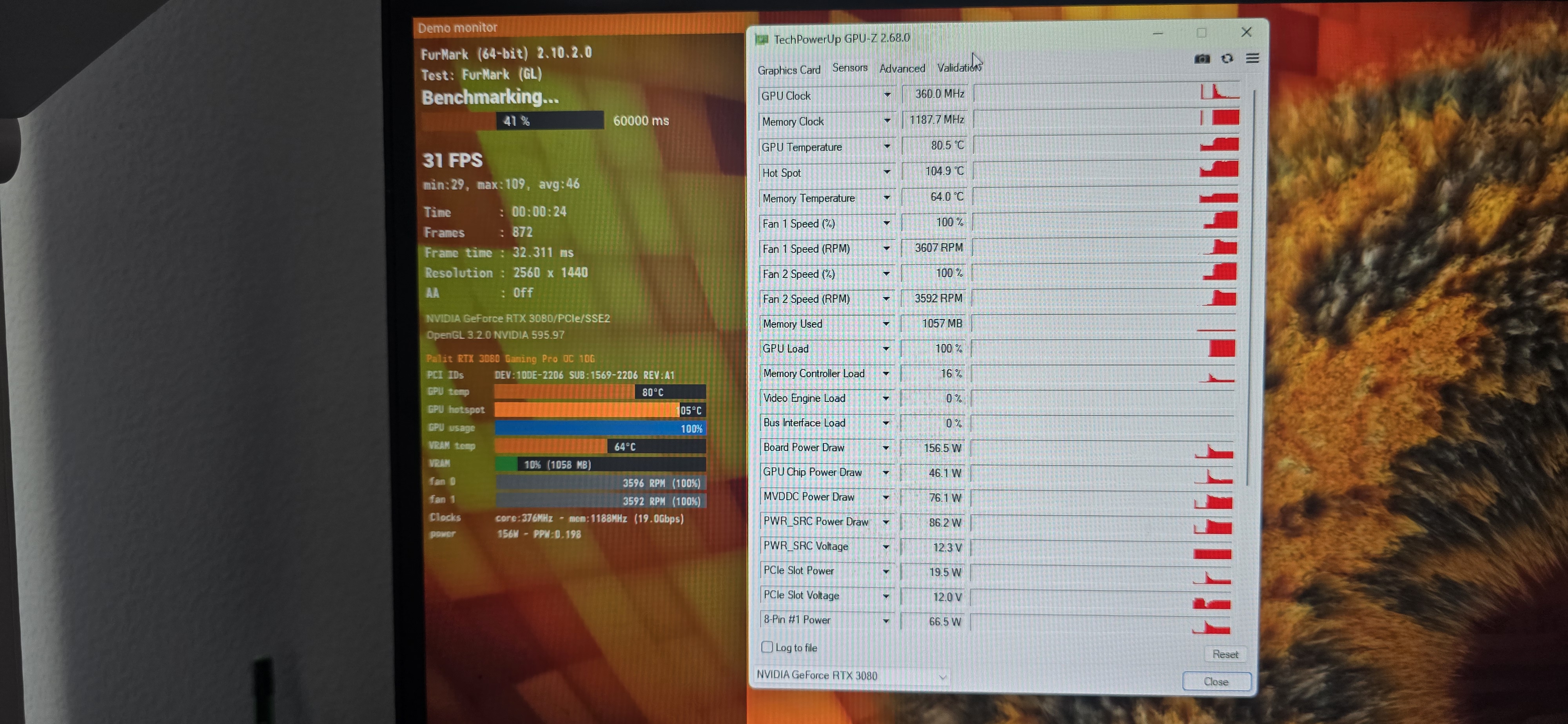
title: “Апгрейд рабочей станции архитектора и анализ троттлинга RTX 3080” date: 2026-06-21T12:00:00+03:00 draft: false description: “Оптимизация локальной лаборатории системного архитектора. Диагностика жесткого термального троттлинга RTX 3080 и план восстановления TDP до 320W.” tags: [Hardware, Workstation, RTX3080, Troubleshooting] Контекст (Бизнес-задача / Проблема): Для Senior-архитектора надежная локальная инфраструктура — это фундамент для проектирования сетей, работы с Docker и подготовки к сертификации CKA (Kubernetes). Я пересобрал свой рабочий стенд на базе Intel Core i5-12400 с 32GB DDR4: на сегодняшний день это лучший баланс цены и производительности для виртуализации. Однако на этапе стресс-тестирования выявилась серьезная аппаратная проблема с Palit RTX 3080. Из-за критического перегрева видеокарта начала душить сама себя, сбрасывая энергопотребление в нагрузке с положенных 320W-330W до 140W для защиты чипа от деградации. Архитектура и Реализация (Решение): Базовая платформа обновлена успешно и работает безупречно. Анализ телеметрии GPU показал, что причина троттлинга кроется в деградации заводских термопрокладок на чипах памяти GDDR6X и зоне VRM. Эта память отличается экстремальным тепловыделением. Инженерное решение требует срочного обслуживания: полной разборки видеокарты, очистки платы и замены термоинтерфейсов на качественные аналоги с точным соблюдением заводских допусков по толщине. Только так можно восстановить эффективный отвод тепла на радиатор и вернуть карте заявленную производительность.
Мониторинг энергопотребления, температур и причин троттлинга GPU в реальном времени
watch -n 1 nvidia-smi –query-gpu=temperature.gpu,temperature.memory,power.draw,clocks.sm,throttle_reasons.active –format=csv