The Context (Business Challenge / Problem): A common dilemma for mid-sized enterprises is balancing infrastructure costs with application stability. Running entirely separate Kubernetes clusters for Development, Staging, and Production doubles or triples the overhead (paying for multiple Control Planes and idle compute resources). However, mixing them in a single cluster is dangerous: a memory leak in a developer’s test pod can consume all node resources, causing a cascading failure that takes down the live Production application. The business needs a way to combine these environments to save money, without ever compromising Production SLA.
The Architecture & Work (Solution): To solve this, I design single-cluster multi-tenancy architectures using strict Node Affinity. Instead of relying on the default Kubernetes scheduler, we logically partition the physical hardware. We label specific high-reliability nodes strictly for production use.
Using the requiredDuringSchedulingIgnoredDuringExecution rule ensures absolute strictness. A production pod will only be scheduled on a production-labeled node. If no production nodes are available, the pod will remain in a Pending state rather than migrating to a weaker Dev node and causing unpredictable behavior.
Here is the YAML deployment architecture demonstrating this strict isolation pattern:
apiVersion: apps/v1
kind: Deployment
metadata:
name: prod-backend-api
namespace: production
spec:
replicas: 3
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
tier: critical
spec:
containers:
- image: nginx:alpine
name: api-server
resources:
requests:
cpu: "2"
memory: "4Gi"
# Strict Node Affinity to ensure workloads only land on Prod hardware
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: environment
operator: In
values:
- production
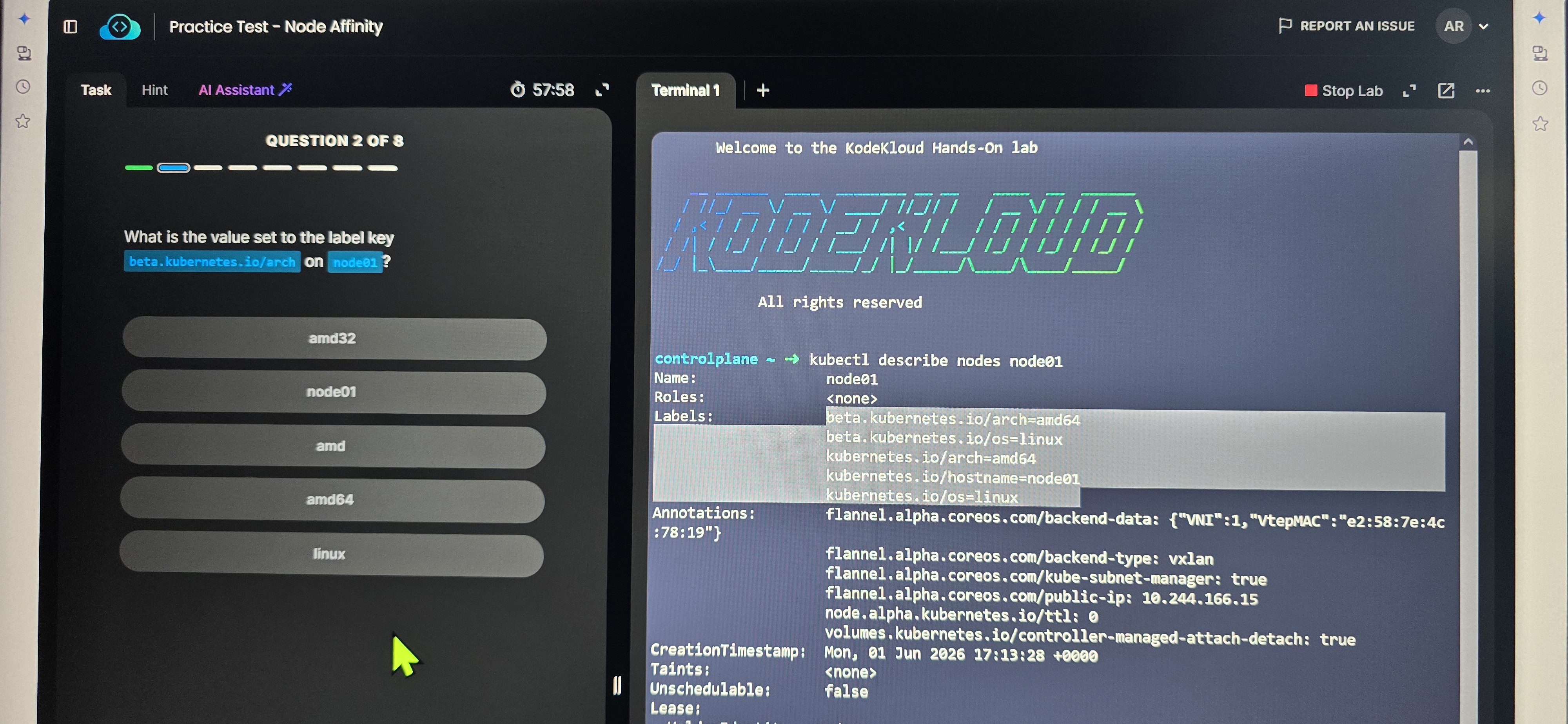
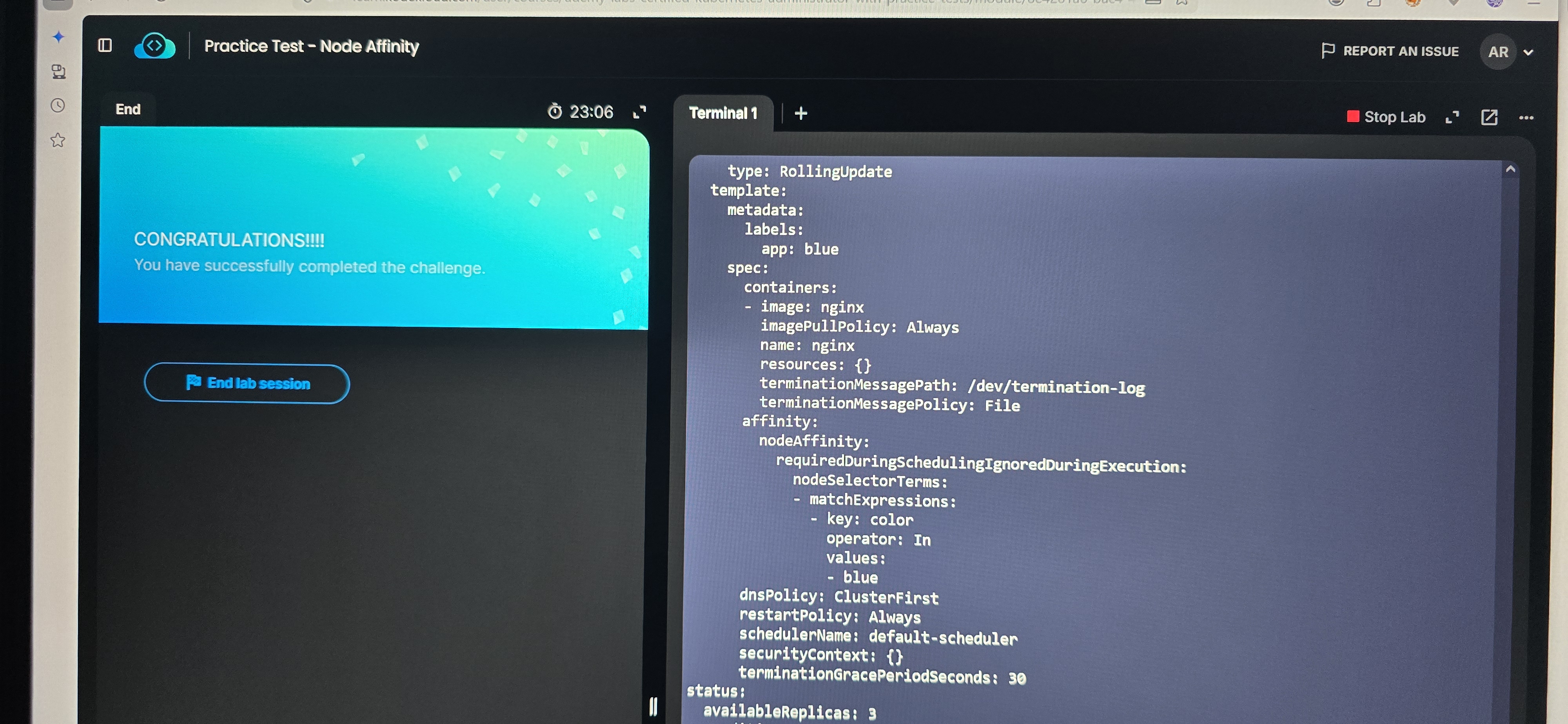
The Takeaway (Business Value): By implementing hardware-level isolation via Node Affinity, businesses achieve the best of both worlds. They cut infrastructure costs by 30-40% through unified cluster management, while guaranteeing 100% predictability for mission-critical workloads. In enterprise architecture, strict boundaries prevent “noisy neighbors”—ensuring that a failure in the lab never touches the live product.